|
26 |
Qiita Advent Calendar 2025 HDLへの投稿 (4) |
Hardware Description Language Advent Calendar 2025の第4弾の記事です。タイトルは「キラキラ星アゲイン」です。 本ブログで説明した記事その他をまとめたものとなります。詳細は本ブログにて。

|
26 |
Qiita Advent Calendar 2025 HDLへの投稿 (4) |
Hardware Description Language Advent Calendar 2025の第4弾の記事です。タイトルは「キラキラ星アゲイン」です。 本ブログで説明した記事その他をまとめたものとなります。詳細は本ブログにて。
|
25 |
Qiita Advent Calendar 2025 HDLへの投稿 (3) |
Hardware Description Language Advent Calendar 2025の第3弾の記事です。タイトルは「聖夜のキラキラ星をBSVで作ろう!」です。 本ブログで説明した記事その他をまとめたものとなります。詳細は本ブログにて。

|
18 |
Qiita Advent Calendar 2025 HDLへの投稿 (2) |
Hardware Description Language Advent Calendar 2025の第2弾の記事です。タイトルは「Ruleを用いないBSVの設計手法」です。
今回ChatGPTと議論しての気づきを3点示します。
|
15 |
Qiita Advent Calendar 2025 HDLへの投稿 |
毎年QiitaではAdvent Calenderを実施していますが、今年2025はHardware Description Language Advent Calendar 2025に記事を書いたので、公開します。第一弾は「巨大FSMのダイエット計画」です。
本ブログで説明した記事その他をまとめたものとなります。詳細は本ブログにて。
|
11 |
GameFSMの改良 (23) |
対応するコードを示します。まず、前景は各色1bitカラー$(g, r, b)$で元と変わりません。
Bit#(1) fg_g1 = !in_exp ? (in_data[2] & pack(fg_dt)) : 1'b0;
Bit#(1) fg_r1 = !in_exp ? (in_data[1] & pack(fg_dt))
: ((in_data[2] | in_data[1] | in_data[0]) & pack(fg_dt));
Bit#(1) fg_b1 = !in_exp ? (in_data[0] & pack(fg_dt)) : 1'b0;
これに4bitの背景を重ね合わせます。背景は$(g_3, g_2, g_1, g_0, r_3, r_2, r_1, r_0, b_3, b_2, b_1, b_0)$の各色4bitカラーです。ただし前稿のとおり、$g_3=r_3=b_3=0$であることからデータは省略でき、3bitずつROMに格納します。
// 背景 GRB333(9bit)
Bit#(3) bg_g3 = bg_data[8:6];
Bit#(3) bg_r3 = bg_data[5:3];
Bit#(3) bg_b3 = bg_data[2:0];
そこからスキャンのタイミングでこのように各色3bitずつ9bitを取り出します。
// 3bit → 4bit (MSB=0 を付加)
Bit#(4) bg_g4 = { 1'b0, bg_g3 };
Bit#(4) bg_r4 = { 1'b0, bg_r3 };
Bit#(4) bg_b4 = { 1'b0, bg_b3 };
次にこのようにMSBに0を詰めて各色4bitとします。
// 背景無効領域は完全黒
Bit#(4) pix_g4 = bg_active ? mixPx(bg_g4, fg_g1) : 4'b0000;
Bit#(4) pix_r4 = bg_active ? mixPx(bg_r4, fg_r1) : 4'b0000;
Bit#(4) pix_b4 = bg_active ? mixPx(bg_b4, fg_b1) : 4'b0000;
前景と背景をブレンドしてdisplay timingでレターボックス化します。以下は前景と背景の合成関数です。
// 背景4bit bg4 と 1bit 前景 fg1 を合成
// 前景の足し込み量は 4'hC 固定(強すぎれば 8〜F で調整)
function Bit#(4) mixPx(Bit#(4) bg4, Bit#(1) fg1);
UInt#(4) ubg = unpack(bg4);
// fg1 が 0 のとき 0000, 1 のとき 1111
Bit#(4) add_b = 4'hC & { fg1, fg1, fg1, fg1 };
UInt#(4) uadd = unpack(add_b);
UInt#(5) sum = zeroExtend(ubg) + zeroExtend(uadd);
UInt#(4) out4 = (sum > 15) ? 15 : truncate(sum);
return pack(out4);
endfunction
図1048.1に完成結果を示します。実際には動画で見るより背景画像は暗くなっており、ゲームの邪魔になることはありません。

記事タイトルはGameFSMの改良ですが、実際に背景画像や星の点滅はGraphicsFSMというグラフィックコントローラに実装しました。背景画像が結構ROMを食うため、Arty 7-35Tでは入らず、Arty 7-100Tでなければ入りませんでした。
|
10 |
GameFSMの改良 (22) |
オリジナルのゲームのうち、アップライト型は前方の背景と下方のブラウン管映像がハーフミラーで合成されています。今回はその効果をFPGAで表現したいと思います。
まず背景画像はここで取得します。画像が大きいので、400x295x12bitにダウンサイズします。$(g_3, g_2, g_1, g_0, r_3, r_2, r_1, r_0, b_3, b_2, b_1, b_0)$という各色4bitカラーの12bitとします。

ただし、背景は前景の邪魔にならないように暗めにαブレンディングするため、結果のMSBは常に0となります。従ってαブレンディング後のデータをROMに格納し、MSBを0として使用することにすれば、各色3bitの画像ですみます。
デコーダ側は、 $$ \text{out} = \min\bigl(\text{bg} + \text{fg} \cdot A,\ 15\bigr) $$
$A$:前景の「足し込む強さ」(いまは (A = 12 = 4'hC))
fg1 = 0 のとき
{fg1,fg1,fg1,fg1} = 0000add_b = 4'hC & 4'b0000 = 0out = min(bg + 0, 15) = bg
→ 背景だけ(透過光だけ)fg1 = 1 のとき
{fg1,fg1,fg1,fg1} = 1111add_b = 4'hC & 4'b1111 = 4'hCout = min(bg + 12, 15)
→ 背景に「反射光分 12段」を足して、4bit 上限 15 を超えたら飽和という「足し算+クリップ」によりハーフミラー効果を再現しています。
|
4 |
GameFSMの改良 (21) |
夜空に瞬く星をシミュレーションする星の点滅プログラムです。
// pack ∘ st のラッパ (packed star)
function Bit#(SizeOf#(StarTwinkle)) ps(U8 x, U8 y, U8 p, U8 phi);
return pack(st(x, y, p, phi));
endfunction
// 星テーブル (packed ビット列)
Bit#(SizeOf#(Vector#(NumStars, StarTwinkle))) starTwinkleBits = {
// ps(x, y, P, phi) 形式
`include "stars_xy.vh"
};
// Vector#(NUM_STARS, StarTwinkle) に変換
Vector#(NumStars, StarTwinkle) starTwinkleTable =
reverse(unpack(starTwinkleBits));
// 1フレーム分、星の点滅を更新する Stmt
// frameCnt : グローバルフレームカウンタ (60Hzで+1される想定)
// baseX,baseY : 星描画の基準座標(ロゴ全体にオフセットを掛けたければここで指定)
function Stmt stepStarField();
let s = starTwinkleTable[i];
let phaseIdx = (truncate(counter) + s.phase) % s.period;
let on = (phaseIdx < (s.period >> 1));
return (seq
for (i <= 0; i < fromInteger(valueOf(NumStars)); i <= i + 1) seq
if (on)
setDot(s.x, s.y, 7);
else
setDot(s.x, s.y, 0);
endseq
endseq);
endfunction
ファイルstars_xy.vhは、サポートプログラムにより元画像から白点の位置を抜き出したデータであり、以下のようなものです。コメントにもありますが、 $$(x, y, P, \phi)$$ の形式です。これをStringでChatGPTに改善してもらったように{ps1, ps2, ...., psn}と並べます。 packed star形式としてps関数を用いて以下のように初期化し、
// loaded 76 stars from stars_xy.csv
// ps(x, y, P, phi) 形式
ps( 0, 0, 64, 19),
ps(204, 1, 16, 7),
ps( 63, 2, 16, 11),
:
ps( 33, 251, 32, 8),
ps(165, 254, 8, 0),
ps(232, 254, 64, 33)
使う場合はあらかじめunpackしてreverseしたテーブルのほうを引いて使います。
ChatGPT 5.1に各種サポートプログラムをpythonで作成してもらった他、bsvについて 9割方はChatによるもので ユーザはデバッグ係となっていました。
ChatGPT 5.1は慣れないbsvこそ時々文法誤りコードを吐くことがあるものの、pythonは完璧な出来映えで一度もバグを入れることはありませんでした。pythonの方が得意な印象ですが、世の中に有るコードベースを考えたら無理もありません。
これ程pythonが得意なら。今後もう人間がpythonを書くことは無くなり、pythonは機械語のような位置付けになるかもしれません。昔は機械語のバイナリを覚えたものですが(C3,00,80,...)それと同じことになりそうです。
幸いbsvはまだそこまで得意ではないので、まだ人間が書く楽しみが残されています。
|
3 |
GameFSMの改良 (20) |
次に夜空の星の点滅プログラムです。8bitレトロマシンとは思えないくらいの立体感のある映像になりました。もともと立体感のある画像だからなのですが。
例によって星の点滅をChatGPTと相談したら3案提示されたのですが、周期と位相を適当にずらす案を採用し、そのコードを書きました。
案3:座標から「周期と位相」を決めるだけの簡単版
擬似乱数すら使わず、各星に違う周期と位相を与えるだけでも、それなりに「ランダムっぽく」見えます。
フレームカウンタ$t$を用意。
星の座標$(x,y)$から、その星固有の周期$P$と位相$\phi$を決める。 例: $$ P = 8 + ((x + 2y) \bmod 5) \quad (8 \sim 12; \text{フレーム周期}) $$ $$ \phi = (3x + y) \bmod P $$
星は次の条件で ON にする。 $$ \text{star_on} = 1 \iff ((t + \phi) \bmod P) < \frac{P}{2} $$
- つまり各星は周期$P$で点滅し、そのうち半分だけ点灯。
- 星ごとに$P$と$\phi$が違うため、全体としてはかなりバラバラに光って見える。
ハード実装としては
- $P$を事前に ROM に入れておくか、座標から組み合わせ回路で計算、
- Pを2の冪にすれば、$\bmod P$の演算も不要

|
1 |
GameFSMの改良 (19) |
ブリッジのコードに怪しいところがあるので、修正中です。さて、オープニング画面を追加したいと思い、bsvコードを書きました。8bit(?)レトロマシンとは思えないくらいの立体感のある映像になりました。
まず画像のロード関数です。元画像はここにあった解像度の高いものを256x256に縮め、さらに色数を4色に落としました。単純にパターンROMに画像を置いてVRAMに転送するだけではあまり面白くないので、RLE (run length encoding)を行いました。
元画像はpythonでRLEしましたが、そのデコーダ部のbsvコードを示します。
// PROM アドレス(1 nibble 単位)
Reg#(PAddr_t) rleAddr <- mkReg(0);
// 展開先の相対座標 (0..255, 0..255)
Reg#(U8) rleX <- mkReg(0);
Reg#(U8) rleY <- mkReg(0);
// 残りピクセル数 256 * 256
Reg#(UInt#(16)) pixelsLeft <- mkReg(0);
// 現在のランの残り長さ (1..256)
Reg#(UInt#(9)) runLen <- mkReg(0);
// 色と長さ nibble
Reg#(Pattern_t) rleColor <- mkReg(0);
Reg#(Pattern_t) rleLenHiNib <- mkReg(0);
Reg#(Pattern_t) rleLenLoNib <- mkReg(0);
// PROM から nibble(Pattern_t) を1つ読み取り、dst に入れ、rleAddr を 1 進める
function Stmt rleNextNibble(Reg#(Pattern_t) dst);
return (seq
action
// PROM アドレスをセット
p_addr <= rleAddr;
endaction
// read timing 調整が必要ならここに noAction を挟む
noAction;
action
// nibble を取り込み
dst <= romdata; // romdata : Pattern_t
rleAddr <= rleAddr + 1; // 次の nibble へ
endaction
endseq);
endfunction
// PROM 上で RLE が始まるニブルアドレス(行256の先頭なら 128*256)
`define RLE_START_ADDR 128*256
`define VRAM_WIDTH 256
`define VRAM_HEIGHT 256
function Stmt rleDecode_org();
return (seq
//------------------------------------------------
// 初期化
//------------------------------------------------
action
// RLE データは PROM の 256 行目から始まる前提
rleAddr <= fromInteger(`RLE_START_ADDR);
// 出力先相対座標
rleX <= 0;
rleY <= 0;
pixelsLeft <= fromInteger(`VRAM_WIDTH * `VRAM_HEIGHT -1);
runLen <= 0;
endaction
//------------------------------------------------
// 全ピクセルを描き終えるまでループ
//------------------------------------------------
while (pixelsLeft != 0) seq
// --- 新しいランを読み込む必要があるなら ---
if (runLen == 0) seq
// color
rleNextNibble(rleColor);
// len_hi
rleNextNibble(rleLenHiNib);
// len_lo
rleNextNibble(rleLenLoNib);
action
UInt#(4) hi = unpack(rleLenHiNib);
UInt#(4) lo = unpack(rleLenLoNib);
// ラン長 L = 16*hi + lo + 1
runLen <= extend(unpack({pack(hi), pack(lo)})) + 1;
endaction
endseq
// --- このランから 1 ピクセル描画 ---
setDot(rleX, rleY, rleColor);
action
pixelsLeft <= pixelsLeft - 1;
runLen <= runLen - 1;
// 256 幅で折り返し
if (rleX == 8'd255) begin
rleX <= 0;
rleY <= rleY + 1;
end
else begin
rleX <= rleX + 1;
end
endaction
endseq // while (pixelsLeft != 0)
endseq);
endfunction
FSM rle_fsm <- mkFSM(rleDecode());
// rleDecodeを起動するラッパ
function Stmt rleDecode();
return (seq
`RUN_FSM(rle_fsm)
endseq);
endfunction
|
21 |
GameFSMの改良 (18) |
過去記事の続きです。GameFSM(ゲームシナリオ)とSoundFSM(サウンドプレーヤ)の間をOneStageというセマフォで接続していて、それを最適化(除去)しようとしたところ、ChatGPTにCDCを考慮していないと怒られてしまいました。「なら作って」と言って同期化ブリッジを作ってもらいました。実際にはやり直しが何度もありましたが。
マルチクロック設計で、2つの非同期クロックドメインにまたがる1段の同期化FIFOを用いています。
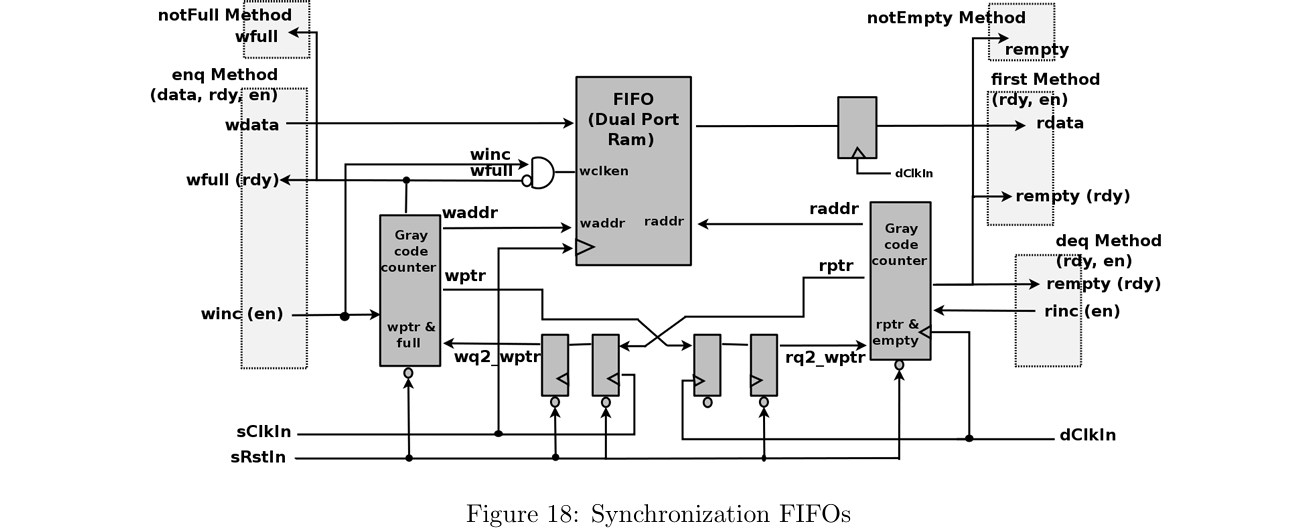
作ってもらったコードを示します。
GSBridge.bsv:
package GSBridge;
import Clocks::*;
typedef Bit#(4) SoundCode_t;
// Game 側 IF:busy を見て !busy のときだけ setReq する前提
interface GSBridgeGameIfc;
method Action setCode(SoundCode_t code); // このサイクルのコード値
method Action setReq (Bool fire); // このサイクルで発行するなら True
// method Bool busy; // バッファ占有中なら True
endinterface
// Sound 側 IF:valid が立ったサイクルで code を取り込む
interface GSBridgeSoundIfc;
method SoundCode_t code; // 取り込まれたコマンド値
method Bool valid; // 新コマンド到着 1 サイクルパルス
endinterface
interface GSBridgeIfc;
interface GSBridgeGameIfc game;
interface GSBridgeSoundIfc sound;
endinterface
(* synthesize, always_ready, always_enabled, no_default_clock, no_default_reset *)
module mkGSBridge#(Clock gameClk, Reset gameRst,
Clock sndClk)
(GSBridgeIfc);
// gameRst を sndClk ドメインに同期させたリセット
Reset sndRst <- mkSyncReset(2, gameRst, sndClk);
// Game→Sound の 4bit コマンド用 Sync FIFO(深さ1)
SyncFIFOIfc#(SoundCode_t) fifo
<- mkSyncFIFO(1, gameClk, gameRst, sndClk);
// Game ドメイン側入力(必ず gameClk/gameRst にぶら下げる)
Wire#(SoundCode_t) w_code <- mkWire(clocked_by gameClk, reset_by gameRst);
Wire#(Bool) w_req <- mkWire(clocked_by gameClk, reset_by gameRst);
// Sound ドメイン側の出力レジスタ(sndClk/sndRst ドメイン)
Reg#(SoundCode_t) r_code <- mkRegU (clocked_by sndClk, reset_by sndRst);
Reg#(Bool) r_valid <- mkReg(False, clocked_by sndClk, reset_by sndRst);
//-------------------------
// Game ドメイン: fire かつ FIFO に空きがあるときだけ enq
//-------------------------
rule rl_enq (w_req && fifo.notFull);
fifo.enq(w_code);
endrule
//-------------------------
// Sound ドメイン: FIFO から 1 件取り出して r_code にラッチ
// valid を 1 サイクルだけ立てる
//-------------------------
rule rl_deq (fifo.notEmpty && !r_valid);
r_code <= fifo.first;
fifo.deq;
r_valid <= True;
endrule
rule rl_clear (r_valid);
r_valid <= False;
endrule
//-------------------------
// Game 側サブインタフェース実装
//-------------------------
interface GSBridgeGameIfc game;
// このサイクルのコード値を保持
method Action setCode(SoundCode_t code);
w_code <= code;
endmethod
// このサイクルで発行するなら fire=True
method Action setReq(Bool fire);
w_req <= fire;
endmethod
// ★ busy は「未消費のコマンドが FIFO にあるかどうか」
// = 元の 1bit セマフォと等価
// method Bool busy;
// return fifo.notEmpty;
// endmethod
endinterface
//-------------------------
// Sound 側サブインタフェース実装
//-------------------------
interface GSBridgeSoundIfc sound;
// 直近に取り込んだコマンド値(valid が 1 のサイクルに有効)
method SoundCode_t code;
return r_code;
endmethod
// 新コマンドが届いたサイクルだけ 1 になるパルス
method Bool valid;
return r_valid;
endmethod
endinterface
endmodule
endpackage

{kind=link}